Introduction to Amazon Aurora Limitless Database

What is Amazon Aurora Limitless Database?
At AWS Re:Invent 2023, the preview of Amazon Aurora Limitless Database was announced. This groundbreaking serverless offering permits access to a single Aurora database, capable of immense write throughput and storage capacity. Traditional Aurora setups needed multiple writers and a complex scaling solution across instances. Presently, the service is by invitation, operating in Aurora PostgreSQL version 15 across various AWS regions.
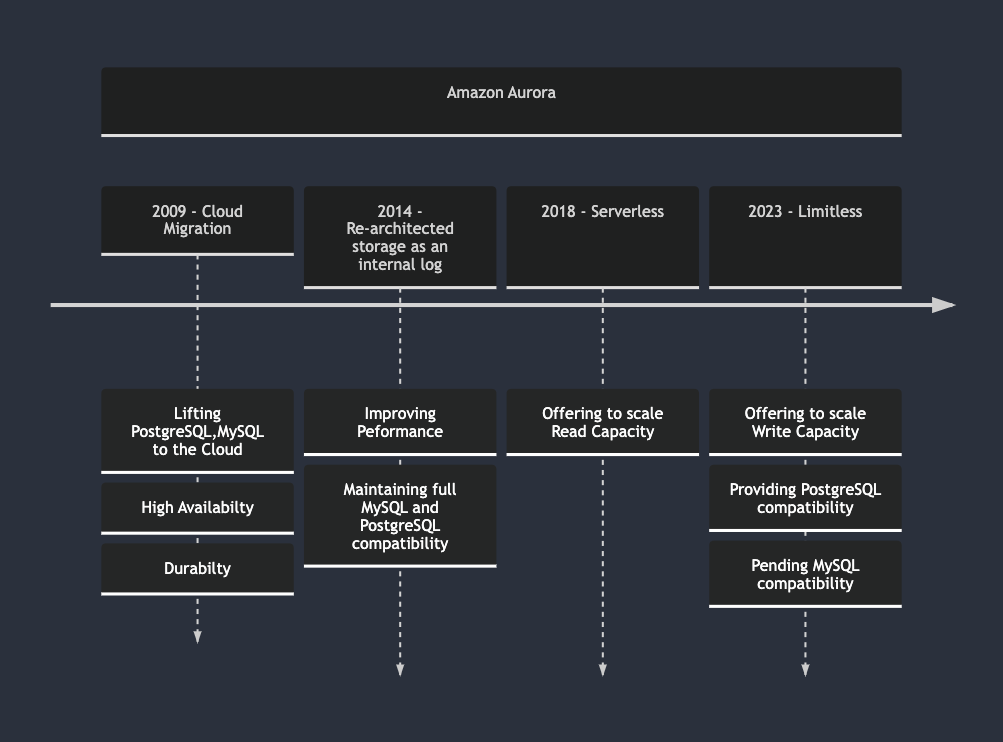
Amazon Aurora Limitless represents a culmination of fifteen years of Amazon’s relational database development. The journey includes migrating databases to cloud-based managed services, enhancing availability and performance, and introducing serverless solutions for extreme scaling.
Comparison of Amazon Aurora Versions
Amazon Aurora Serverless v1 vs Serverless v2 vs Provisioned vs Limitless
A comparative table below highlights the key features and differences between Aurora Serverless v1, Serverless v2, Provisioned, and Limitless versions. Notably, the Limitless version, in its preview stage, does not support MySQL.
| Amazon Aurora Serverless v1 | Amazon Aurora Serverless v2 | Amazon Aurora Provisioned | Amazon Aurora Limitless – Preview | |
| Scale Up Time | From 10 seconds to 10 minutes. Must find scaling point; otherwise remain unchanged or force (will cause active queries to be dropped) | In seconds, without waiting for scaling point | In hours: requires creating a snapshot and restoring it to a larger instance | In milliseconds |
| Scale Down Time | Up to 15 minutes | < 1 minute | N/A: Static capacity | < 1 minute |
| Capacity Increments | Scale-up in double increments | Scale-up in increments of 0.5 ACU | N/A: Static capacity | TBD |
| Starting Capacity | 1 ACU, but can be brought down to 0 (pausing cluster) | 0.5 ACU | N/A: Static capacity | TBD |
| Scaling | Single instance. Both the writer and reader share the same autoscaling policy. | Scale up/down automatically. Single Writer Up to 15 reader instances | Scale up/down managed by the user. Single Writer Up to 15 reader instances | Multiple |
| DB engine versions support | Aurora MySQL 2: MySQL 5.7 Aurora PostgreSQL:10.12, 10.14 | Aurora MySQL 3: MySQL 8 Aurora PostgreSQL:All 15, 14, and 13 versions | Aurora MySQL 3: MySQL 8 Aurora PostgreSQL:All 15, 14, and 13 versions | MySQL is not supported Aurora PostgreSQL: 15 |
| Billing | By ACU | By ACU | By Instance size + IOPS | By ACU |
Amazon Aurora Database – Serverless v1 vs Serverless v2 vs Provisioned vs Limitless
Understanding Amazon Aurora Limitless
Amazon Aurora Limitless Under the Hood
Amazon Aurora Limitless takes the capabilities of regular databases further by increasing both the reading and writing abilities beyond what one database instance can normally do. This is made possible through a new feature called the DB Shard Endpoint. Despite this new feature, users of PostgreSQL can still connect to the database in the usual way, using the familiar Cluster (Aurora Writer) and Reader (Aurora Replica) endpoints.
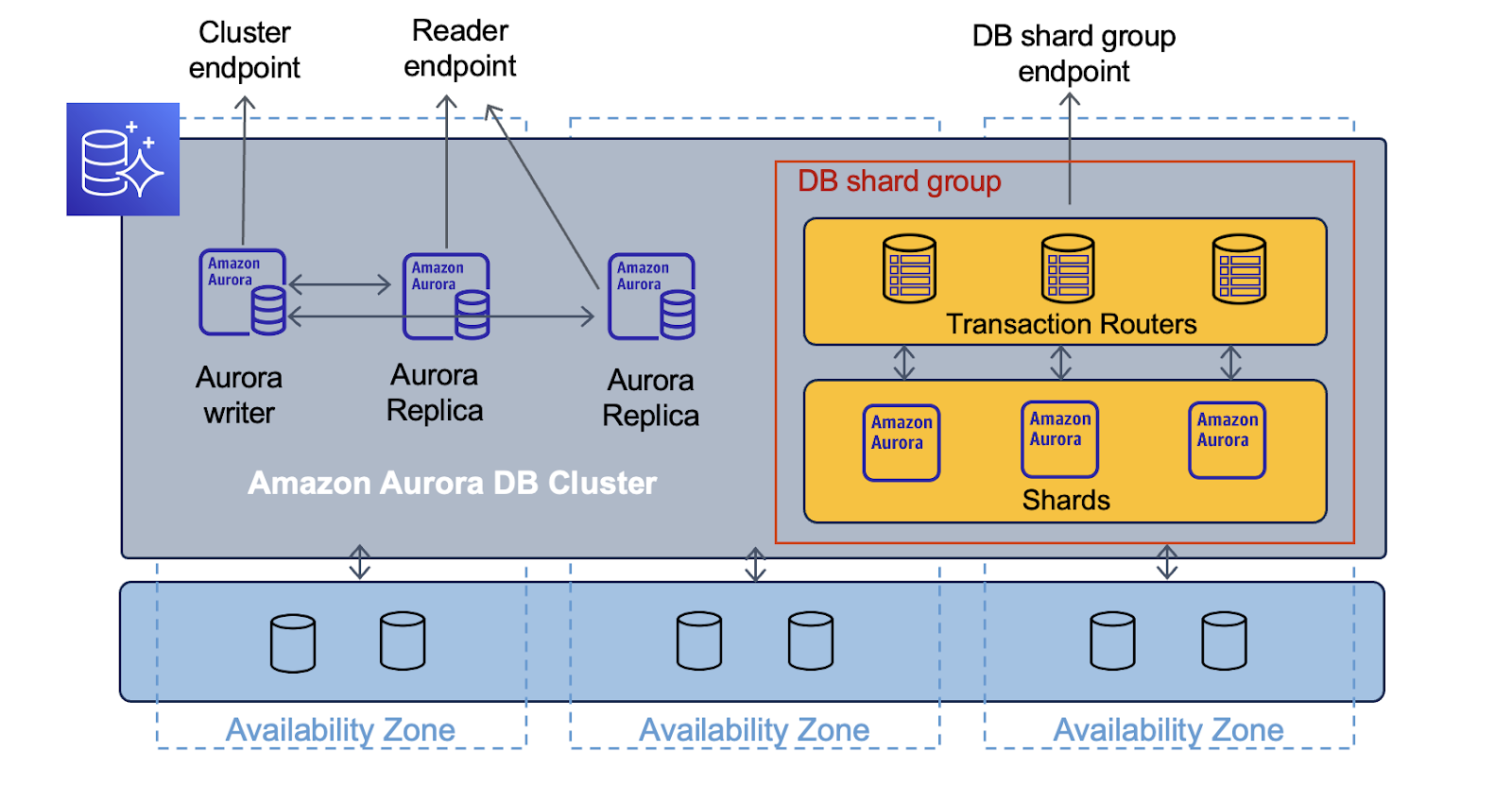
Amazon Aurora Limitless has two key components that handle data: Transaction Routers and Data Shards. The Transaction Routers deal with all the data requests from different apps, adjusting their workload based on how much data they’re handling. They plan out how to best handle these data requests and put together information from across the database. The Data Shards, supported by Aurora’s distributed storage, actually carry out these data requests. They manage specific parts of the database and have complete sets of certain tables for easy access and organization.
There are two main types of tables used to store data in Aurora Limitless: Shared Tables and Reference Tables. Shared Tables are parts of a bigger table, spread across different areas of the database. This helps in managing large sets of data more efficiently. Reference Tables, on the other hand, are found in every part of the database. They make linking data together quicker by reducing the need to move data around.
For users of PostgreSQL, moving to Amazon Aurora Limitless is easy as there’s no need to change how you usually ask for data (write queries). But to take full advantage of Aurora Limitless, you’ll need to use some new SQL commands.
Shared Tables
Shared tables are optimized for large-scale data intake. The SQL example below demonstrates setting a table as ‘sharded’ with a specified shard key.
SET rds_aurora.limitless_create_table_mode='sharded';
SET rds_aurora.limitless_create_table_shard_key='{bid}';
CREATE TABLE pgbench_branches
(
bid INT NOT NULL,
bbalance INT,
filler CHAR
);
The SQL statements above set the table pgbench_branches as sharded and specify the field bid as shard key. The data is split among the shards based on the value of bid.
Reference Table
Reference tables are designed for frequent reads/joins and occasional writes, with no shard key required.
SET rds_aurora.limitless_create_table_mode='reference';
CREATE TABLE pgbench_rates
(
pid INT NOT NULL PRIMARY KEY,
term INT,
rate NUMERIC NOT NULL
);Transactions
Aurora Limitless supports two types of isolation transaction levels: Read Committed and Repeatable Read. Every query in a transaction sees different data when the isolation level is set to Read Committed. Conversely, a Repeatable Read guarantees that every query gets the same data in a transaction.
![Read Committed - distributed [5]](https://lh7-us.googleusercontent.com/chcrf6Ecm0OXS9R5KpEWSsy3EtRaqL_GdhQFq2SXnmb_GLV1UEjx6-OhUfcmllbP-zqUPDpINTpP0Y1v-H91moGr5-9UlLD4vZOj2YwmhOBhtiPHvBbidLhAljPYQpDsz5MP4apgRSYuYfUEZZ1vvsI)
![Repeatable Read - distributed [5]](https://lh7-us.googleusercontent.com/U3HHGRnoFMJI4WqoM5lvQRBcRIdZovO2T9HEQSqM2asKSyLfXq33p0JPum52Y4Pry1Fsj2eljOkLaIjOYBV6QA8ScCNUAJAWB0hCPTfW_9Zv7CHr1MDkkxhVUq7cER-261vksWFXz4wa40uInZhfwAU)
The SQL syntax does not change to specify the isolation transaction level. Aurora Limitless ensures ACID compliance by using two concepts: snapshots and synchronized clocks. Both elements allow to determine when a transaction is committed or rolled back.
Is Amazon Aurora Limitless Truly Limitless?
While Aurora Limitless can handle vast amounts of data, PostgreSQL table storage is capped at 32TB. The choice of an appropriate shard key is crucial for scaling. Similarly, reference tables must also be under 32TB. The maximum capacity of Aurora Limitless is determined by ACUs at cluster creation. (See table Amazon Aurora Database – Serverless v1 vs Serverless v2 vs Provisioned vs Limitless)
Amazon Aurora Limitless vs Amazon DynamoDB
An alternative solution to scale easily your application by partitioning keys is Amazon DynamoDB Database. After the capacity units for reading and writing are set, and a complementary configuration to handle autoscaling, the solution is ready without requiring much management.
It’s important to define which serverless database fits better. If an application does queries on data and the resultset returns less than 1Mb, typically in real-time cases, DynamoDB is a better option. On the other hand, if the queries extract a large portion of data, in a batch-oriented architecture, Amazon Aurora performs better.
Basically the decision to define which service is better is based on the size of the resultset. Large extractions are the opposite of event driven architecture. Surely you can find another case when both solutions can coexist [5].
Closing thoughts on Amazon Aurora Limitless
The Amazon Aurora Limitless Database is currently in preview, you can request an invitation to participate. It runs in an Aurora PostgreSQL cluster with version 15 in the AWS US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Tokyo), and Europe (Ireland) Regions. Give it a try and share your early experience. Below there is list of open questions that hopefully will be answered with the official release:
- Compared to Serverless v2, Is the limitless version able to scale to 0 ACUs? (Serverless v2 scale to 0.5 ACUs)
- Does the limitless version support RDS API?
- Does the limitless version support the Serializable Isolation Level?
- Is there a way to avoid downtime of schema changes on large tables?
References
- From 0 to Limitless, the 15-year odyssey of Amazon relational database product line
- Join the preview of Amazon Aurora Limitless Database
- https://aws.amazon.com/blogs/database/evaluate-amazon-aurora-serverless-v2-for-your-provisioned-aurora-clusters/#:~:text=Amazon%20Aurora%20provisioned%20database%20instance,r6g.
- https://www.postgresql.org/docs/current/transaction-iso.html
- Achieve Extreme Scalability with Amazon Aurora Limitless Database at AWS re:Invent 2023 – video
- AWS — When to use Amazon Aurora instead of DynamoDB